
线程池是一种多线程处理形式,处理过程中将任务添加到队列,然后在创建线程后自动启动这些任务。线程池线程都是后台线程。每个线程都使用默认的堆栈大小,以默认的优先级运行,并处于多线程单元中。如果某个线程在托管代码中空闲(如正在等待某个事件),则线程池将插入另一个辅助线程来使所有处理器保持繁忙。如果所有线程池线程都始终保持繁忙,但队列中包含挂起的工作,则线程池将在一段时间后创建另一个辅助线程但线程的数目永远不会超过最大值。超过最大值的线程可以排队,但他们要等到其他线程完成后才启动。—-百度百科
我们首先来看下四种常用的线程池吧,下面是四种常用线程池的介绍
1 | // 我们首先来看下四种常用的线程池吧 |
但这里我们不推荐使用Executors去创建线程池,是不符合编程规范的,推荐使用ThreadPoolExecutor去创建
线程池的优点
管理一组工作线程,通过线程池复用线程有以下几点优点:
- 减少资源创建:减少内存开销,创建线程占用内存(特别是并发比较高的生产环境)
- 降低系统开销:创建线程需要时间,会延迟处理的请求
- 提高稳定性:避免无限创建线程引起的OutOfMemoryError
Executors创建方法的弊端:
1)newFixedThreadPool和newSingleThreadExecutor:
主要问题是堆积的请求处理队列可能会耗费非常大的内存,甚至OOM.
2)newCachedThreadPool和newScheduledThreadPool:
主要问题是线程数最多数是Integer.MAX_VALUE,可能会创建数量非常多的线程,甚至OOM.
我们简单看看这个语句
1 | private final ExecutorService cachedThreadPool = Executors.newCachedThreadPool(); |
关注一下源码实现
1 | public static ExecutorService newCachedThreadPool() { |
1 | public ThreadPoolExecutor(int corePoolSize, |
底层其实还是Executors对ThreadPoolExecutor进行的封装,推荐使用其实还是让使用者们夺取关注一下其底层的实现,根据业务场景的需要做适合的调整
这里说一下每个参数的含义
构造函数参数说明:
- corePoolSize => 线程池核心线程数量
- maximumPoolSize => 线程池最大数量
- keepAliveTime => 空闲线程存活时间
- unit => 时间单位
- workQueue=> 线程池所使用的缓冲队列
- threadFactory => 线程池创建线程使用的工厂
- handler => 线程池对拒绝任务的处理策略
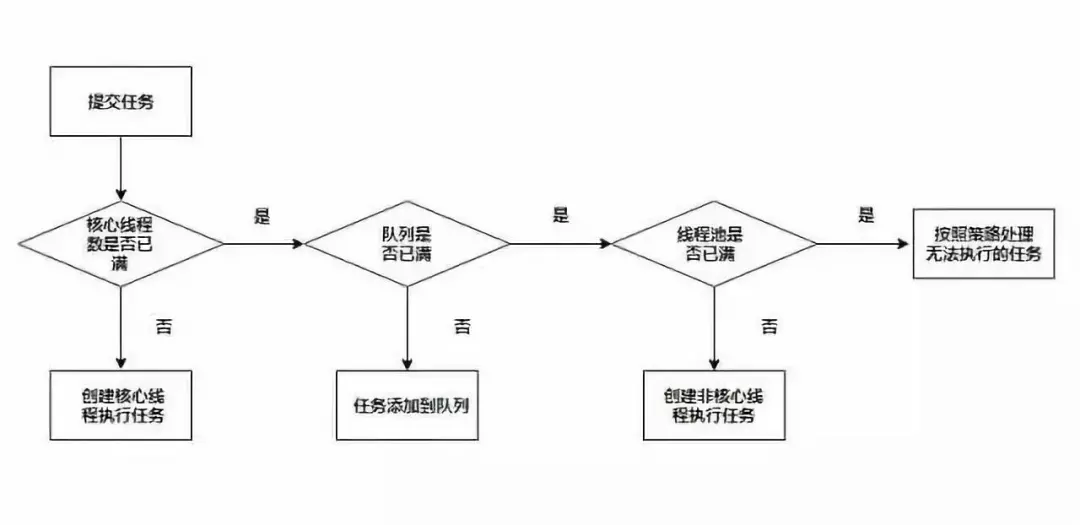
前几个参数比较容易理解,这里说一下任务队列与线程池拒绝策略
首先任务队列我们又可以叫做阻塞队列:
ArrayBlockingQueue
ArrayBlockingQueue 是 BlockingQueue 接口的有界队列实现类,底层采用数组来实现。其并发控制采用可重入锁来控制,不管是插入操作还是读取操作,都需要获取到锁才能进行操作。
SynchronousQueue
它是一个特殊的队列,它的名字其实就蕴含了它的特征 – - 同步的队列。为什么说是同步的呢?这里说的并不是多线程的并发问题,而是因为当一个线程往队列中写入一个元素时,写入操作不会立即返回,需要等待另一个线程来将这个元素拿走;同理,当一个读线程做读操作的时候,同样需要一个相匹配的写线程的写操作。这里的 Synchronous 指的就是读线程和写线程需要同步,一个读线程匹配一个写线程。
LinkedBlockingDeque
LinkedBlockingDeque就是一个双向队列,任何一端都可以进行元素的出入。底层基于单向链表实现的阻塞队列,可以当做无界队列也可以当做有界队列来使用。
LinkedBlockingQueue
LinkedBlockingQueue是一个单向队列,只能一端出一端入的单向队列结构,是有FIFO特性的,并且是通过两个ReentrantLock和两个Condition来实现的。底层基于单向链表实现的阻塞队列,可以当做无界队列也可以当做有界队列来使用。
DelayQueue
是一个支持延时获取元素的无界阻塞队列。内部用 PriorityQueue 实现。
PriorityBlockingQueue
PriorityBlockingQueue是带排序的 BlockingQueue 实现,其并发控制采用的是 ReentrantLock,队列为无界队列(ArrayBlockingQueue 是有界队列,LinkedBlockingQueue 也可以通过在构造函数中传入 capacity 指定队列最大的容量,但是 PriorityBlockingQueue 只能指定初始的队列大小,后面插入元素的时候,如果空间不够的话会自动扩容)。
简单地说,它就是 PriorityQueue 的线程安全版本。不可以插入 null 值,同时,插入队列的对象必须是可比较大小的(comparable),否则报 ClassCastException 异常。它的插入操作 put 方法不会 block,因为它是无界队列(take 方法在队列为空的时候会阻塞)。
PS:队列大小无限制,常用的为无界的LinkedBlockingQueue,使用该队列做为阻塞队列时要尤其当心,当任务耗时较长时可能会导致大量新任务在队列中堆积最终导致OOM。阅读代码发现,Executors.newFixedThreadPool 采用就是 LinkedBlockingQueue,而楼主踩到的就是这个坑,当QPS很高,发送数据很大,大量的任务被添加到这个无界LinkedBlockingQueue 中,导致cpu和内存飙升服务器挂掉。
线程池的拒绝策略
所有拒绝策略都实现了接口 RejectedExecutionHandler
1 | public interface RejectedExecutionHandler { |
AbortPolicy
直接抛出拒绝异常(继承自RuntimeException),会中断调用者的处理过程,所以除非有明确需求,一般不推荐
1 | public static class AbortPolicy implements RejectedExecutionHandler { |
CallerRunsPolicy
在调用者线程中(也就是说谁把 r 这个任务甩来的),运行当前被丢弃的任务。
只会用调用者所在线程来运行任务,也就是说任务不会进入线程池。
如果线程池已经被关闭,则直接丢弃该任务。
1 | public static class CallerRunsPolicy implements RejectedExecutionHandler { |
DiscardOledestPolicy
丢弃队列中最老的,然后再次尝试提交新任务。
1 | public static class DiscardOldestPolicy implements RejectedExecutionHandler { |
DiscardPolicy
默默丢弃无法加载的任务。
1 | public static class DiscardPolicy implements RejectedExecutionHandler { |
自定义线程池拒绝策略
通过实现 RejectedExecutionHandler 接口扩展
示例:dubbo,直接继承的 AbortPolicy ,加强了日志输出,并且输出dump文件(JVM内存文件快照的输出)
1 | public class AbortPolicyWithReport extends ThreadPoolExecutor.AbortPolicy { |