
MapReduce:计算框架和编程模型
Google的三驾马车
USNew把计算机科学分为4个领域:人工只能、编程语言、系统以及理论、其中的系统领域有两大顶级会议,一个是ODSI(USENIX conference on Operating Systems Design and Implementation),另一个是SOSP(ACM Symposium on Operating Systems Principles),这两个会议在业界的分量非常重,如果把近十年关于这两个会议的重要论文收录到一本书,就可以看作是操作系统和分布式系统的一本教科书。
从2003年到2006年,Google分别在ODSI与SOSP发表了3篇论文,引起了业界对于分布式系统的广泛讨论,这三篇论文分别是:
- SOSP2003: The Google File System;
- OSDI2004: MapReduce:Simplifed Data Processing on Large Clusters
- ODSI2006: Bigtable:A Distributed Storage System for Structured Data
在2006年,Google首席执行官施密特提出了云计算这个词语,Google的这3篇论文也被称为Google的三驾马车,代表Google大数据处理的基石、云计算的基础。不过值得注意的是,虽然Google作为业界领军者经常会将自己的技术开源出来,但是客观的讲,Google开源出来的技术并不是内部使用的最新技术,中间甚至会有代差,这也侧面反映出Google的技术实力。
MapReduce编程模型与MaoReduce计算框架
在发表的第2篇文章中,Google很明确的表示MapReduce是其实现的一个分布式计算框架,其编程模型名为MapReduce。开源社区基于这篇论文的内容,基本实现了一个分布式计算框架也叫MapReduce。但一些书籍和网上的资料在提到MapReduce的时候并未说明,容易造成困惑,其实Google拿编程模型的名字直接作为计算框架的名字这种例子还有很多,例如Dataflow。而MapReduce有两个含义,一般来说,在说道计算框架时,我们指的是开源社区的Mapreduce计算框架,但随着新一代计算框架例如Spark、Flink的崛起,开源社区的MapReduce计算框架在生产环境中使用的越来越少,逐渐退出舞台。
MapReduce的第二个含义是一种编程模型,这种编程模型来源于古老的函数式编程思想,在Lisp等比较老的语言中也有相应的实现,并随着计算机CPU单核性能以及核心数量的飞速提升在分布式计算中焕发出新的生机。
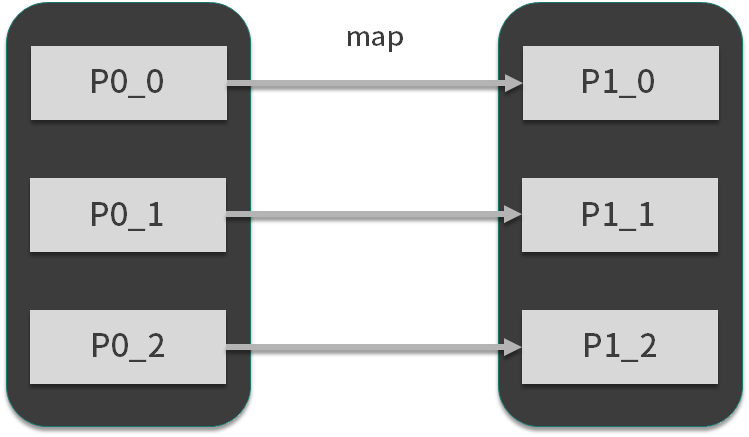
MapReduce模型将数据处理方式抽象为map和reduce,其中map也叫映射,顾名思义,它表现的是数据的一对一映射,通常完成数据转换的工作,如下图所示:
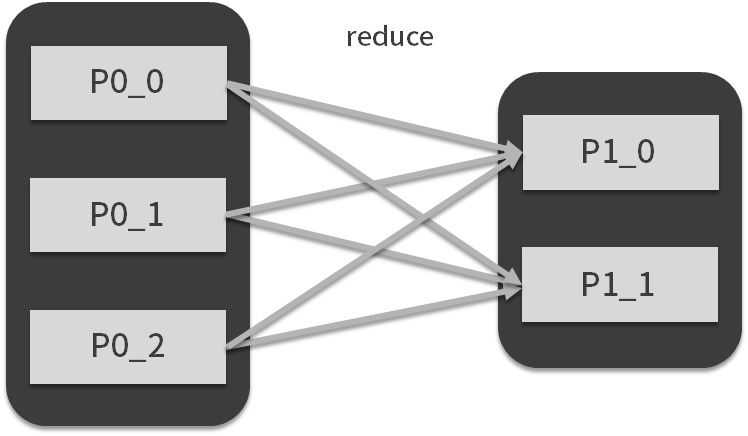
reduce被称为归约,它表示另外一种映射方式,通常完成聚合的工作,如下图所示:
圆角框可以看成是一个集合,里面的方框可以看成某条要处理的数据,箭头表示映射的方式和要执行的自定义函数,运用MapReduce编程思想,我们可以实现以下内容:
- 将数据集(输入数据)抽象成集合;
- 将数据处理过程用map与reduce进行表示
- 在自定义函数中实现自己的逻辑
这样就可以实现从输入数据到结果数据的处理流程(映射)了
并发与并行
一般来说,底层的东西越简单,那么上层的东西就越复杂,对于MapReduce编程模型来说,map与reduce的组合加上用户自定义函数,对于业务的表现力是非常强的,这里举一个分组聚合的例子,如下图所示: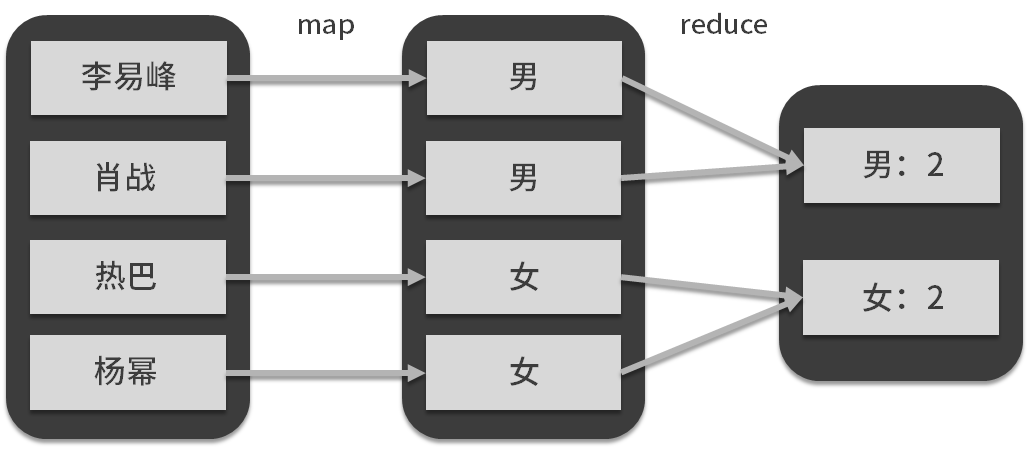
map端的用户自定义函数与map算子对原始数据人名进行了转换,生成了组标签:性别,reduce端的自定义函数与reduce算子对数据按照标签进行了聚合(汇总)
Mapreduce认为,再复杂的数据处理流程也无非是这两种映射方式的组合,例如map+map+reduce,或者reduce后面接map,等等,在下面这张图里你可以看到相对复杂的一种组合形式:
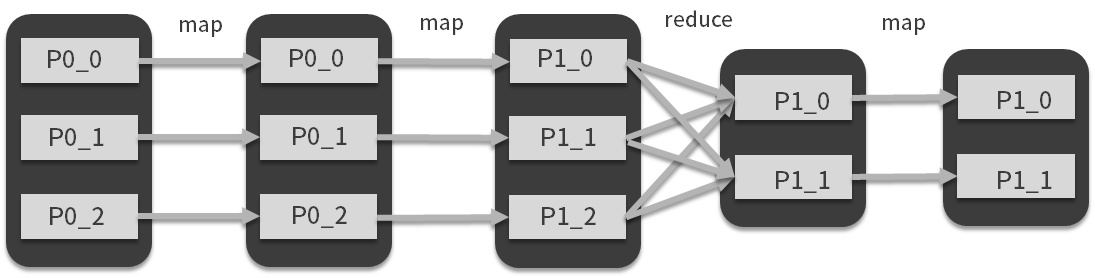
很多支持函数式编程的语言,对于语言本身自带的几何数据结构,都会提供map、reduce算子,现在,我们可以很同意的将第一个圆角方框想象成一个数十条数据的集合,它是内存中的集合变量,那么实现上图中的变换,对于计算机来说,难度并不大,就算数据量再大些,我们也可以考虑将不同方框和计算流程交给同一台计算机的CPU不同的核心进行计算,这就是我们说的并行和并发。
如何理解分布式计算框架的编程接口与背后的工程实现
随着数据集的继续增大,要处理的数据超过了计算内存的大小,那么就算是逻辑非常简单的流程,也要考虑中间结构的存储,比如计算过程涉及到硬盘和内存之前的数据交换等等之类的工程实现的问题,虽然在这个过程中上面3步并没有发生变化,但是背后实现的系统复杂度大大提高了。
将上图中的圆角框想象成一个极其巨大的数据集,而方框想象成大数据集的一部分,我们会发现,对于从输入数据到结果数据的映射需求来说,前面 3 步仍然适用,只是这个集合变得非常大。
但是由于数据量的急剧扩大,相比于刚才的第 2 种情况,背后工程实现的复杂度会成倍增加,当整个数据集的容量和计算量达到 1 台计算机能处理的极限的时候,我们就会想办法把图中方框所代表的数据集分别交给不同的计算机来完成,那么如何调度计算机,如何实现 reduce 过程中不同计算机之间的数据传输等问题,就是 Spark 基于 MapReduce 编程模型的分布式实现,这也是我们常常所说的分布式计算。
从上图可以看出,在 reduce 过程中,会涉及到数据在不同计算机之间进行传输,这也是 MapReduce 模型下的分布式实现的一个关键点,后面我们会讲到 Spark 是如何做的。
看到这里,你可能对分布式运算有一个感性的认识,以小见大,函数式语言本身就提供了类似于 map、reduce 的操作,如下图第 1、2 行代码:

1、2 行是函数式编程语言 Scala 对于集合的处理,3、4 行是 Spark 对集合的处理,逻辑同样是对集合元素都加 1 再过滤掉小于等于 1 的元素并求和。对于 Spark 来说,处理几十 GB到几十 TB 的数据集,第2行代码或者说第4行代码同样适用,只是 list 变得比较特殊,它不是只存在于一台计算机的内存里,而是存在于多台计算机的磁盘和内存上。
现在,我们可以这样理解基于 MapReduce 编程模型的分布式计算框架,其编程接口与普通函数式语言的数据处理并没有什么不同(甚至可以说完全一样),但是背后的工程实现千差万别,而像 Spark、MapReduce 这样的框架,它们的目标都是尽力为用户提供尽可能简单的编程接口以及高效地工程实践。从这个角度上来讲,我们可以把 Spark 看成是一种分布式计算编程语言,它的终极目标是希望达到这样一种体验:让用户处理海量数据集时与处理内存中的集合变量并没有什么不同。
MapReduce 这种思想或者编程模型已经出现几十年了,不变的是思想,变得是使用场景和实现方法。我相信未来一定会有效率优于 Spark 的计算框架出现,就像 Spark 优于普通的编程语言一样。