
OLAP场景
读多于写
不同与事务处理OLTP的场景,比如电商场景中加购物车、下单、支付需要在原地进行大量insert、update、delete操作,数据分析OLAP场景通常是将数据批量导入后,进行任意维度的灵活探索、BI工具洞察、报表制作等。数据一次性写入后,分析师需要尝试从各个角度对数据做挖掘、分析,直到发现其中的商业价值、业务变化趋势等信息,这是一个需要反复试错、不断调整、持续优化的过程,其中数据的读取次数远多于写入次数,这就要求底层数据库为这个特点做专门设计,而不是盲目采用传统数据库的技术架构。
大宽表,读大量行但是少量列,结果集较小
在OLAP场景中,通常存在一张或是几张多列的大宽表,列数高达数百甚至上千列,对数据分析处理时,选择其中的少数几列作为维度列,其他少数几列作为指标列,然后对全表或某一个交大范围内的数据做聚合计算,这个过程会扫描大量的行数据,但是只用到了其中的少数列,而聚合计算的结果相比于动辄数十亿的原始数据,也明显小得多。
数据批量写入,且数据不更新或者少更新
OLTP类业务对于延时要求更高,要避免让客户等待造成业务损失,而OLAP类业务,由于数据量非常大,通常更加关注写入吞吐,要求海量数据能够尽快导入完成。一旦导入完成,历史数据往往作为存档,不会再做更新、删除操作。
无需事务,数据一致性要求低
OLAP类业务数据对于事务需求较少,通常是导入历史日志数据,或搭配一款事务性数据库并实时从事务性数据库中进行数据同步,多数OLAP系统都支持最终一致性。
灵活多变,不适合预先建模
分析场景下,随着业务变化要及时调整分析维度,挖掘方法,以尽快发现数据价值,更新业务指标,而数据仓库中通常存储着海量的历史数据,调整代价十分高昂,预先建模技术虽然可以在特定的场景中加速计算,但是无法满足业务灵活多变的发展需求,维护成本过高。
什么是ClickHouse?
ClickHouse是一个用于联机分析(OLAP)的列式数据库管理系统(DBMS)
在传统的行式数据库系统中,数据按如下顺序存储:
| Row | WatchID | JavaEnable | Title | GoodEvent | Time |
|---|---|---|---|---|---|
| 0 | 89354350662 | 1 | Investor Relations | 1 | 2016-05-18 05:19:20 |
| 1 | 90329509958 | 0 | Contact us | 1 | 2016-05-18 08:10:20 |
| 2 | 89953706054 | 1 | Mission | 1 | 2016-05-18 07:38:00 |
| N | … | … | … | … | … |
处于同一行中的数据总是被物理的存储在一起
常见的行式数据库系统有:MySQL、Postgres和MS SQL Server。
在列式数据库系统中,数据按如下的顺序存储
| Row: | 0 | 1 | 2 | N |
|---|---|---|---|---|
| WatchID | 89354350662 | 90329509958 | 89953706054 | … |
| JavaEnable | 1 | 0 | 1 | … |
| Title | Investor Relations | Contact us | Mission | … |
| GoodEvent | 1 | 1 | 1 | … |
| Time | 2016-05-18 05:19:20 | 2016-05-18 08:10:20 | 2016-05-18 07:38:00 | … |
这些示例只显示了数据的排列顺序。来自不同列的值被单独存储,来自同一列的数据被存储在一起。
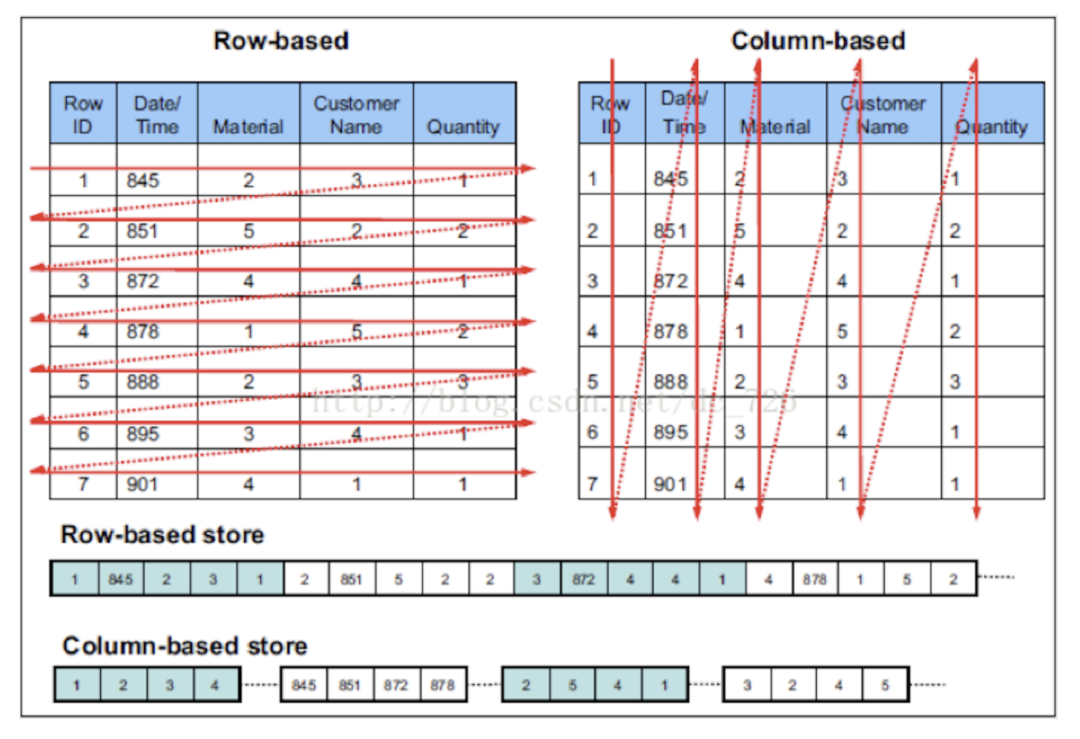
常见的列式数据库有: Vertica、 Paraccel (Actian Matrix,Amazon Redshift)、 Sybase IQ、 Exasol、 Infobright、 InfiniDB、 MonetDB (VectorWise, Actian Vector)、 LucidDB、 SAP HANA、 Google Dremel、 Google PowerDrill、 Druid、 kdb+。
不同的数据存储方式适用不同的业务场景,数据访问的场景包括:进行了何种查询、多久查询一次以及各类查询的比例;每种类型的查询(行、列和字节)读取多少数据;读取数据和更新之间的关系;使用的数据集大小以及如何使用本地的数据集;是否使用事务,以及它们是如何进行隔离的;数据的复制机制与数据的完整性要求;每种类型的查询要求的延迟与吞吐量等等。
系统负载越高,依据使用场景进行定制化就越重要,并且定制将会变的越精细。没有一个系统能够同时适用所有不同的业务场景。如果系统适用于广泛的场景,在负载高的情况下,要兼顾所有的场景,那么将不得不做出选择。是要平衡还是要效率?
OLAP场景的关键特征
- 绝大多数是读请求
- 数据以相当大的批次(> 1000行)更新,而不是单行更新;或者根本没有更新。
- 已添加到数据库的数据不能修改。
- 对于读取,从数据库中提取相当多的行,但只提取列的一小部分。
- 宽表,即每个表包含着大量的列
- 查询相对较少(通常每台服务器每秒查询数百次或更少)
- 对于简单查询,允许延迟大约50毫秒
- 列中的数据相对较小:数字和短字符串(例如,每个URL 60个字节)
- 处理单个查询时需要高吞吐量(每台服务器每秒可达数十亿行)
- 事务不是必须的
- 对数据一致性要求低
- 每个查询有一个大表。除了他以外,其他的都很小。
- 查询结果明显小于源数据。换句话说,数据经过过滤或聚合,因此结果适合于单个服务器的RAM中
很容易可以看出,OLAP场景与其他通常业务场景(例如,OLTP或K/V)有很大的不同, 因此想要使用OLTP或Key-Value数据库去高效的处理分析查询场景,并不是非常完美的适用方案。例如,使用OLAP数据库去处理分析请求通常要优于使用MongoDB或Redis去处理分析请求。
输入/输出
- 针对分析类查询,通常只需要读取表的一小部分列。在列式数据库中你可以只读取你需要的数据。例如,如果只需要读取100列中的5列,这将帮助你最少减少20倍的I/O消耗。
- 由于数据总是打包成批量读取的,所以压缩是非常容易的。同时数据按列分别存储这也更容易压缩。这进一步降低了I/O的体积。
- 由于I/O的降低,这将帮助更多的数据被系统缓存。
例如,查询«统计每个广告平台的记录数量»需要读取«广告平台ID»这一列,它在未压缩的情况下需要1个字节进行存储。如果大部分流量不是来自广告平台,那么这一列至少可以以十倍的压缩率被压缩。当采用快速压缩算法,它的解压速度最少在十亿字节(未压缩数据)每秒。换句话说,这个查询可以在单个服务器上以每秒大约几十亿行的速度进行处理。这实际上是当前实现的速度。
CPU
由于执行一个查询需要处理大量的行,因此在整个向量上执行所有操作将比在每一行上执行所有操作更加高效。同时这将有助于实现一个几乎没有调用成本的查询引擎。如果你不这样做,使用任何一个机械硬盘,查询引擎都不可避免的停止CPU进行等待。所以,在数据按列存储并且按列执行是很有意义的。
有两种方法可以做到这一点:
- 向量引擎:所有的操作都是为向量而不是为单个值编写的。这意味着多个操作之间的不再需要频繁的调用,并且调用的成本基本可以忽略不计。操作代码包含一个优化的内部循环。
- 代码生成:生成一段代码,包含查询中的所有操作。
这是不应该在一个通用数据库中实现的,因为这在运行简单查询时是没有意义的。但是也有例外,例如,MemSQL使用代码生成来减少处理SQL查询的延迟(只是为了比较,分析型数据库通常需要优化的是吞吐而不是延迟)。
请注意,为了提高CPU效率,查询语言必须是声明型的(SQL或MDX), 或者至少一个向量(J,K)。 查询应该只包含隐式循环,允许进行优化。
数据有序存储
ClickHouse支持在建表时,指定将数据按照某些列进行sort by。
排序后,保证了相同sort key的数据在磁盘上连续存储,且有序摆放。在进行等值、范围查询时,where条件命中的数据都紧密存储在一个或若干个连续的Block中,而不是分散的存储在任意多个Block, 大幅减少需要IO的block数量。另外,连续IO也能够充分利用操作系统page cache的预取能力,减少page fault。
数据TTL
在分析场景中,数据的价值随着时间流逝而不断降低,多数业务出于成本考虑只会保留最近几个月的数据,ClickHouse通过TTL提供了数据生命周期管理的能力。
ClickHouse支持几种不同粒度的TTL:
1) 列级别TTL:当一列中的部分数据过期后,会被替换成默认值;当全列数据都过期后,会删除该列。
2)行级别TTL:当某一行过期后,会直接删除该行。
3)分区级别TTL:当分区过期后,会直接删除该分区。
ClickHouse计算层
ClickHouse在计算层做了非常细致的工作,竭尽所能榨干硬件能力,提升查询速度。它实现了单机多核并行、分布式计算、向量化执行与SIMD指令、代码生成等多种重要技术。
多核并行
ClickHouse将数据划分为多个partition,每个partition再进一步划分为多个index granularity,然后通过多个CPU核心分别处理其中的一部分来实现并行数据处理。
在这种设计下,单条Query就能利用整机所有CPU。极致的并行处理能力,极大的降低了查询延时。
分布式计算
除了优秀的单机并行处理能力,ClickHouse还提供了可线性拓展的分布式计算能力。ClickHouse会自动将查询拆解为多个task下发到集群中,然后进行多机并行处理,最后把结果汇聚到一起。
在存在多副本的情况下,ClickHouse提供了多种query下发策略:
- 随机下发:在多个replica中随机选择一个;
- 最近hostname原则:选择与当前下发机器最相近的hostname节点,进行query下发。在特定的网络拓扑下,可以降低网络延时。而且能够确保query下发到固定的replica机器,充分利用系统cache。
- in order:按照特定顺序逐个尝试下发,当前一个replica不可用时,顺延到下一个replica。
- first or random:在In Order模式下,当第一个replica不可用时,所有workload都会积压到第二个Replica,导致负载不均衡。first or random解决了这个问题:当第一个replica不可用时,随机选择一个其他replica,从而保证其余replica间负载均衡。另外在跨region复制场景下,通过设置第一个replica为本region内的副本,可以显著降低网络延时。
向量化执行与SIMD
ClickHouse不仅将数据按列存储,而且按列进行计算。传统OLTP数据库通常采用按行计算,原因是事务处理中以点查为主,SQL计算量小,实现这些技术的收益不够明显。但是在分析场景下,单个SQL所涉及计算量可能极大,将每行作为一个基本单元进行处理会带来严重的性能损耗:
1)对每一行数据都要调用相应的函数,函数调用开销占比高;
2)存储层按列存储数据,在内存中也按列组织,但是计算层按行处理,无法充分利用CPU cache的预读能力,造成CPU Cache miss严重;
3)按行处理,无法利用高效的SIMD指令;
ClickHouse实现了向量执行引擎(Vectorized execution engine),对内存中的列式数据,一个batch调用一次SIMD指令(而非每一行调用一次),不仅减少了函数调用次数、降低了cache miss,而且可以充分发挥SIMD指令的并行能力,大幅缩短了计算耗时。向量执行引擎,通常能够带来数倍的性能提升。
应用
这里总结一下java通过TCP调用的实现
Maven依赖导入
1 | <!-- (推荐) shaded 版本,自 2.3-stable 起可用 --> |
批量查询demo
1 | package examples; |
任务式查询Demo
1 | package examples; |
普通查询Demo
1 | package examples; |