
服务器基本参数确认
首先我们需要明确,服务器的CPU,内存,磁盘情况
CPU
CPU总核数 = 物理CPU个数 * 每颗物理CPU的核数
总逻辑CPU数 = 物理CPU个数 * 每颗物理CPU的核数 * 超线程数
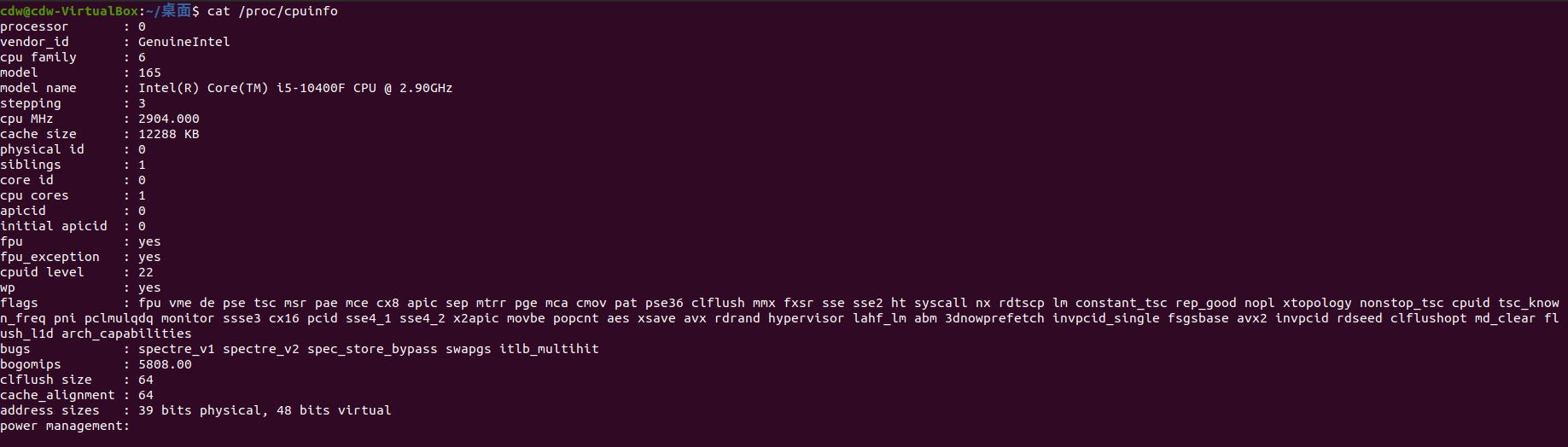
查看CPU的信息(型号)
1 | cat /proc/cpuinfo | grep name | cut -f2 -d: | uniq -c |
查看物理CPU个数
1 | cat /proc/cpuinfo | grep "physical id" | sort | uniq | wc -l |
查看每个物理CPU中core的个数(即核数)
1 | cat /proc/cpuinfo | grep "cpu cores" | uniq |
查看逻辑CPU的个数
1 | cat /proc/cpuinfo | grep "processor" | wc -l |
以我的电脑为例
内存
1 | free -h |
free 命令显示系统内存的使用情况,包括物理内存,交换内存(swap)和内核缓冲区内存
total:总计物理内存的大小
used:已使用多大
free:可用有多少
shared:多喝进程共享的内存总额
Buffers/cached:磁盘缓存的大小
从应用程序的角度来说,可用内存 = 系统 free mamory + buffers + cached

这里我分到虚拟机的内存是4G
这里展开讲讲交换空间,swap space 是磁盘上的一块区域,可以是一个分区,也可以是一个文件。当系统物理内存吃紧时,Linux会将内存中不长访问的数据保存到swap上,这样系统就有更多的物理内存为各个进程服务,这里要注意,读写磁盘的性能和读写内存的性能完全不是一个级别。
磁盘
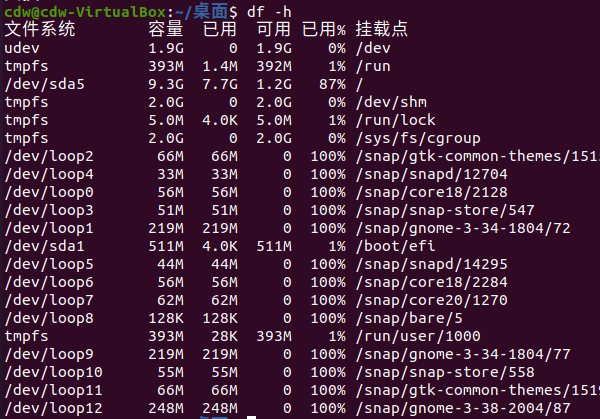
查看Linux磁盘状态
1 | df -h |
用于显示Linux系统的磁盘利用率
Filesystem:指定文件系统的名称
Size:大小
Used:已使用的大小
Avail:可以使用的大小
Use%:使用的百分比
Mounted on:文件系统的挂载点
这里我们也展开说说什么事挂载
Linux 系统中“一切皆文件”,所有文件都放置在以根目录为树根的树形目录结构中。在 Linux 看来,任何硬件设备也都是文件,它们各有自己的一套文件系统(文件目录结构)。
因此产生的问题是,当在 Linux 系统中使用这些硬件设备时,只有将Linux本身的文件目录与硬件设备的文件目录合二为一,硬件设备才能为我们所用。合二为一的过程称为“挂载”。
服务器状态监控
top
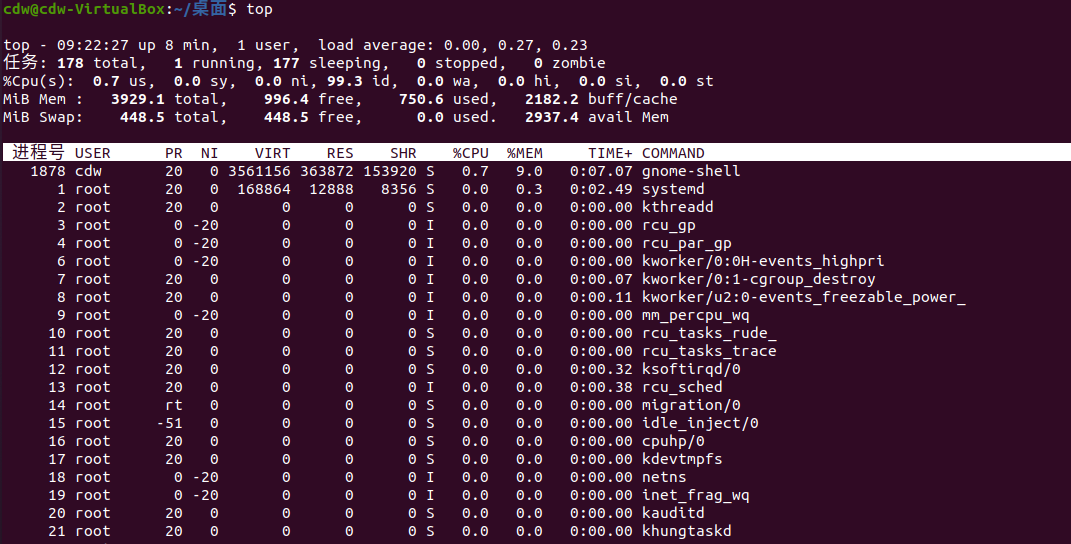
top命令经常用来监控linux的系统状况,是常用的性能分析工具,能够实时显示系统中各个进程的资源占用情况
第一行
1 | top - 09:22:27 up 8 min, 1 users, load average: 0.00, 0.27, 0.23 |
top- 当前时间 up 系统的运行时间,当前登录用户数, 系统负载,即任务队列的平均长度。三个数值分别为1分钟、5分钟、15分钟前到现在的平均值
这里 load average 展开讲一下,如果这个数除以逻辑CPU的数量 < 0.7 表示系统运行很流程没有问题,如果大于1了,那么表示有进程在等待CPU处理了,大于3的时候,表示系统在超负荷运转,这个时候就需要排查一下CPU负载过高的问题。
第二行
1 | Tasks: 178 total, 1 running, 177 sleeping, 0 stopped, 0 zombie |
Tasks:进程总数,正在运行的进程数,睡眠的进程数,停止的进程数,僵尸进程数
第三行
1 | Cpu(s): 0.7 us, 0.0 sy, 0.0 ni, 99.3 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st |
%Cpu(s): 用户空间占用CPU百分比,内核空间占用CPU百分比,用户进程空间内改变过优先级的进程占用CPU百分比, 空闲CPU百分比, 硬中断占用CPU的百分比,软中断占用CPU的百分比
第四行
1 | KiB Mem : 3929.1 total, 996.4 free, 750.6 used, 2182.2 buff/cache |
物理内存总量, 空闲的内存总量,使用的物理内存总量,用作内核缓存的内存量
第五行
1 | KiB Swap: 448.5 total, 448.5 free, 0.0 used. 2937.4 avail Mem |
交换区总量,空闲的交换区总量,使用的交换区总量,代表可用于进程下一次分配的物理内存数量
第六行
例子:PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
PID:进程ID
USER:进程所有者的用户名
PR:优先级
NI:nice值,负值标识高优先级,正值标识低优先级
VIRT:进程使用的虚拟内存总量
RES:进程使用的,未被换出的物理内存大小
SHR:共享内存大小
S:进程状态 D=不可终端的睡眠状态、R=运行、S=睡眠、T=跟踪/停止、Z=僵尸进程
%CPU:上次更新到现在的CPU时间占用百分比
%MEM:进程使用的物理内存百分比
TIME+:进程使用的CPU时间总计
COMMAND:命令行
top命令同时也支持很多快捷键
M 根据驻留内存大小进行排序。
P 根据CPU使用百分比大小进行排序。
T 根据时间/累计时间进行排序。 iostat
m 切换显示内存信息。
iostat
iostat也是比较重要的状态监控命令,特别是针对服务器磁盘io情况的细致监控
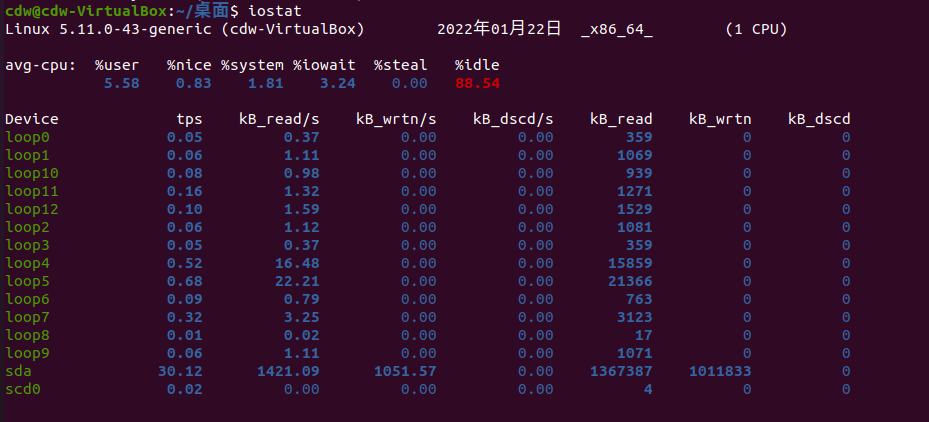
cpu属性值说明:
%user:CPU处在用户模式下的时间百分比。
%nice:CPU处在带NICE值的用户模式下的时间百分比。
%system:CPU处在系统模式下的时间百分比。
%iowait:CPU等待输入输出完成时间的百分比。
%steal:管理程序维护另一个虚拟处理器时,虚拟CPU的无意识等待时间百分比。
%idle:CPU空闲时间百分比。
tps:该设备每秒的传输次数
kB_read/s:每秒从设备(drive expressed)读取的数据量;
kB_wrtn/s:每秒向设备(drive expressed)写入的数据量;
kB_read: 读取的总数据量;
kB_wrtn:写入的总数量数据量;
备注:
如果%iowait的值过高,表示硬盘存在I/O瓶颈
如果%idle值高,表示CPU较空闲
如果%idle值高但系统响应慢时,可能是CPU等待分配内存,应加大内存容量。
如果%idle值持续低于10,表明CPU处理能力相对较低,系统中最需要解决的资源是CPU。
磁盘的I/O性能直接影响应用程序的性能,在一个有频繁读写的应用中,如果磁盘I/O性能得不到满足,就会导致应用停滞。好在现今的磁盘都采用了很多方法来提高I/O性能,比如常见的磁盘RAID技术。
通过RAID技术组成的磁盘组,就相当于一个大硬盘,用户可以对它进行分区格式化、建立文件系统等操作,跟单个物理硬盘一模一样,唯一不同的是RAID磁盘组的I/O性能比单个硬盘要高很多,同时在数据的安全性也有很大提升。
根据磁盘组合方式的不同,RAID可以分为RAID0,RAID1、RAID2、RAID3、RAID4、RAID5、RAID6、RAID7、RAID0+1、RAID10等级别,我们用的比较多的RAID0、RAID1、RAID5,这里进行简单介绍。
RAID 0:通过把多块硬盘粘合成一个容量更大的硬盘组,提高了磁盘的性能和吞吐量。这种方式成本低,要求至少两个磁盘,但是没有容错和数据修复功能,因而只能用在对数据安全性要求不高的环境中。
RAID 1:也就是磁盘镜像,通过把一个磁盘的数据镜像到另一个磁盘上,最大限度地保证磁盘数据的可靠性和可修复性,具有很高的数据冗余能力,但磁盘利用率只有50%,因而,成本最高,多用在保存重要数据的场合。
RAID5:采用了磁盘分段加奇偶校验技术,从而提高了系统可靠性,RAID5读出效率很高,写入效率一般,至少需要3块盘。允许一块磁盘故障,而不影响数据的可用性。
服务器优化
设置swap交换空间和swappiness的比例设置
首先简单的说一下swap分区的作用,其实linux系统下的swap分区与windows下的虚拟内存差不多一个意思,swap空间的作用可简单这样理解:当系统的物理内存不够用的时候,就需要将物理内存中的一部分空间释放出来,以供当前运行的程序使用。那些被释放的空间可能来自一些很长时间没有什么操作的程序,这些被释放的空间被临时保存到swap空间中,等到那些程序要运行时,再从swap中恢复保存的数据到 内存中。这样,系统总是在物理内存不够时,才进行swap交换。
也就是说linux 会使用硬盘的一部分做为swap分区,用来进行进程调度–进程是正在运行的程序–把当前不用的进程调成‘等待(standby)‘,甚至‘睡眠(sleep)’,一旦要用,再调成‘活动(active)’,睡眠的进程就躺到SWAP分区睡大觉,把内存空出来让给‘活动’的进程。
如果内存够大,那么这个时候应该让 linux 不必太多的使用swap分区, 可以通过修改swappiness的数值。当swappiness为0的时候表示最大限度使用物理内存,然后才是 swap空间,当swappines为100的时候,则表示积极的使用swap分区,并且把内存上的数据及时的搬运到swap空间里面。
在CentOS、Red Hat、ubuntu等系统中,swappiness的默认值都为60,如果Linux服务器的内存很小,比如说低于4G,那么可以不用更改这个值,因为毕竟考虑到内存不够用而去借用swap的情况。而相对于很多服务器来说,目前还是建议设置在值为25以下,如果超过了8G内存,而且目前内存使用量还有剩余的话,建议直接将swappiness改成0,这样可以最大限度的使用物理内存,减少硬盘的负载,同时加快速度。也避免在使用Memcached的时候出现”memcached timeout error because of slow response”这样的错误。
相关命令
查看swappiness当前设置的值:
1 | cat /proc/sys/vm/swappiness |
修改swappiness的值:(这里指永久修改为10)
1 | echo vm.swappiness = 10 >> /etc/sysctl.conf |
刷新一下
1 | sysctl -p |
使用vm.dirty_ratio和vm.dirty_background_ratio更好的Linux磁盘缓存和性能
脏页是linux内核中的概念,因为硬盘的读写速度远赶不上内存的速度,系统就把读写比较频繁的数据事先放到内存中,以提高读写速度,这就叫高速缓存,linux是以页作为高速缓存的单位,当进程修改了高速缓存里的数据时,该页就被内核标记为脏页,内核将会在合适的时间把脏页的数据写到磁盘中去,以保持高速缓存中的数据和磁盘中的数据是一致的。
1 | sysctl -a | grep dirty |
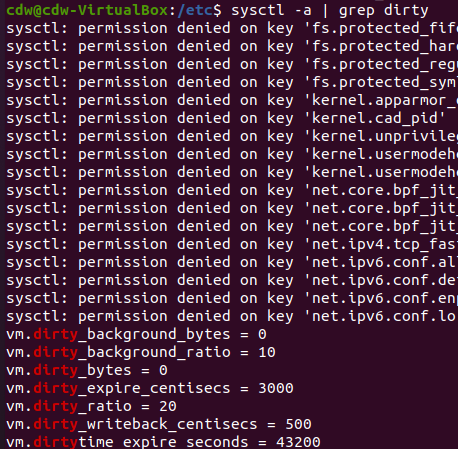
vm.dirty_background_ratio :
是内存可以填充“脏数据”的百分比。这些“脏数据”在稍后是会写入磁盘的,pdflush/flush/kdmflush这些后台进程会稍后清理脏数据。举一个例子,我有32G内存,那么有3.2G的内存可以待着内存里,超过3.2G的话就会有后来进程来清理它。
vm.dirty_ratio:
是绝对的脏数据限制,内存里的脏数据百分比不能超过这个值。如果脏数据超过这个数量,新的IO请求将会被阻挡,直到脏数据被写进磁盘。这是造成IO卡顿的重要原因,但这也是保证内存中不会存在过量脏数据的保护机制。
vm.dirty_background_bytes和vm.dirty_bytes是
指定这些参数的另一种方法。如果设置_bytes版本,则_ratio版本将变为0,反之亦然。
vm.dirty_expire_centisecs :
指定脏数据能存活的时间。在这里它的值是30秒。当 pdflush/flush/kdmflush 进行起来时,它会检查是否有数据超过这个时限,如果有则会把它异步地写到磁盘中。毕竟数据在内存里待太久也会有丢失风险。
vm.dirty_writeback_centisecs:
指定多长时间 pdflush/flush/kdmflush 这些进程会起来一次。
修改这些参数的方法可见swappiness,这里不多赘述